
I am continuing evaluation of some text processing tools that I began in an earlier open notebook post on the same topic.
I also had an idea that perhaps I should open my PDF documents in Word, then re-save them as HTML. That workflow might standardize the formatting to something less “bizarre” in terms of the underlying formatting.
iPub PDF to HTML for mac (ipub-pdf-to-html-for-mac.dmg)
Only 15 files at a time can be converted with this trial ware version, and only 5 pages at a time (which is really not problematic for most LinkedIN profile PDFs, at least among those in my collection).
I chose Amber Budden, Rebecca Koskela, Mill Michener, and myself to convert. The output location is as follows:
/Volumes/TOSHIBA/ipubsoft-output
As before “TannerJessel.pdf” is available for evaluation on this open notebook’s media management page (See TannerJessel pdf file).
The output is all one page, which is good. It appears to only go to 2 pages – this may be a limitation of the trialware.
[code language= “HTML”]<DIV style="position:absolute;top:912;left:54"><nobr><span class="ft02">Skills & Expertise</span></nobr></DIV> <DIV style="position:absolute;top:946;left:54"><nobr><span class="ft09"><b>Science<br>Higher Education<br>Teaching<br>Grant Writing<br>Research<br>Lifesciences<br>Data Analysis</b></span></nobr></DIV>[/code]
Two words have spaces, Grant Writing and Data analysis. In this version all non breaking spaces have %nbsp; which might be helpful.
There is some structure, which is potentially useful.
In my “converted” LinkedIN profile, my information is presented as follows:
<DIV style="position:absolute;top:57;left:54"><nobr><span class="ft00"><b>Tanner Jessel</b></span></nobr></DIV> <DIV style="position:absolute;top:94;left:54"><nobr><span class="ft01">Web Content Strategist, Bioinformatics & Internet Services Specialist</span></nobr></DIV> <DIV style="position:absolute;top:125;left:54"><nobr><span class="ft02">mountainsol[edited out]gmail.com</span></nobr></DIV> <DIV style="position:absolute;top:179;left:54"><nobr><span class="ft03">Summary</span></nobr></DIV>
Note I edited out my e-mail address. I’m not sure why LinkedIN gave me this.
Both Amber and I have an “Experience” section. Unfortunately this is rendered differently:
class="ft02"
For both converted HTML documents. (Mine is “ft03” not ft02).
I surmise the fonts are just assigned based on what’s encountered. For example, my e-mail address comes before the section heading. Since all of the saved LinkedIN profiles are different, this might pose a serious problem that will lead me to choose PDF to XLS conversion instead of PDF to HTML.
The next PDF to HTML software conversion on my list to try [Note: after trying this I DO NOT recommend this] is: cbsidlm-sp1_0_150-PDFtoHTML-SEO-100684.dmg. This freeware is a bit tricky since it appears to want to install some add-ons, but by selecting a custom install it appears I can circumvent that.
This appears to be a GUI for the command line version I tried in a previous post.
“OS X PDFtoHTML” is based on “pdftohtml” from Gueorgui Ovtcharov and Rainer Dorsch which is currently maintained by Mikhail Kruk.
It still might be interesting to see if there are some other options I was overlooking.
There’s a drag and drop interface.
Dragging the icon for the file to convert results in this path:
/Users/apple/Documents/linkedin profiles-WG-Members/TannerJessel.pdf
Clicking “Convert PDFtoHTML” creates a new folder on the desktop (PtH.output.14.04.10_15.36.06) but nothing is in it. And, nothing is in the original folder. I’m going to say this app does not work and is probably malware or spyware since it attaches plug-ins and add-ons and messes with your default settings for browsers. So, I’ll be un-installing that with AppCleaner.
Third to test is “Wondershare PDF Editor Pro” 278 MB. This is also trial ware and will leave a watermark on saved documents. The trial ware limit is 5 pages – my own LinkedIN is fairly long and the trialware preserved it. However it appears you must convert one at a time, and I don’t think that will work for my purposes. Nice app for other purposes though.
The headings are closer to what I want though. For example, main headings for Experience is as follows:
<span style="font-size:15.942;color:#999999;">Experience</span>
The same is true for Amber Budden:
<span style="font-size:15.942;color:#999999;">Experience</span>
And the same is true for “Education:”
<span style="font-size:15.942;color:#999999;">Education</span>
I also accidentally converted the document to a .doc file, and used the opportunity presented to test converting from .doc to .html from within Word.
The “Experience” section looks like this:
<span style='font-size:16.0pt;color:#999999'>Experience<o:p></o:p></span>
An advantage of doing it this way is that everything is contained within one single HTML file, instead of one HTML file for multiple PDF pages.
The number of steps required is a bit frustrating though (Convert to Word, Convert to HTML), especially if each one has to be processed individually.
Just a quick check of the remaining headings:
<span style='font-size:16.0pt;color:#999999'>Skills & Expertise<o:p></o:p></span>
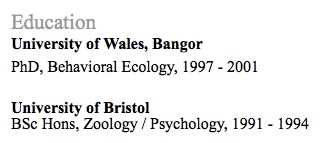
Here is the entire “Education” section (for comparison see the image):
<p style='margin-left:.5in;line-height:14.4pt;mso-line-height-rule: exactly;mso-pagination:none;mso-layout-grid-align:none;text-autospace:none'><span style='font-size:16.0pt;color:#999999'>Education<o:p></o:p></span></p>
<p style='margin-left:.5in;line-height:19.5pt;mso-line-height-rule: exactly;mso-pagination:none;mso-layout-grid-align:none;text-autospace:none'><b><span style='font-size:12.0pt;color:black'>University of Wales, Bangor<o:p></o:p></span></b></p>
<p style='margin-left:.5in;line-height:14.85pt;mso-line-height-rule: exactly;mso-pagination:none;mso-layout-grid-align:none;text-autospace:none'><span style='font-size:12.0pt;color:black'>PhD, Behavioral Ecology, 1997 - 2001<o:p></o:p></span></p>
<p style='line-height:18.1pt;mso-line-height-rule:exactly; mso-pagination:none;mso-layout-grid-align:none;text-autospace:none'><span style='font-size:12.0pt'><o:p> </o:p></span></p>
<p style='margin-left:.5in;line-height:10.8pt;mso-line-height-rule: exactly;mso-pagination:none;mso-layout-grid-align:none;text-autospace:none'><b><span style='font-size:12.0pt;color:black'>University of Bristol<o:p></o:p></span></b></p>
<p style='margin-left:.5in;line-height:14.85pt;mso-line-height-rule: exactly;mso-pagination:none;mso-layout-grid-align:none;text-autospace:none'><span style='font-size:12.0pt;color:black'>BSc Hons, Zoology / Psychology, 1991 - 1994<o:p></o:p></span></p>
It looks like “line-height” is what distinguishes “place of education” from the date and time.
Right now this approach (PDF to Word to HTML) appears to have a bit more reliable structure than any of the other unstructured text processing options I’ve looked at so far.
Still, I’m wondering if the extreme variability in the data (due to different data that LinkedIN has collected through successive iterations of the site) doesn’t make something like NOSql a worthwhile approach. I’ll look into that more later – a quick search turned up <http://www.computerworld.com/s/article/9247555/With_MongoDB_2.6_NoSQL_database_gets_a_speed_boost>. And if I were to convert the content to Text instead of PDF, then perhaps it could easily be converted to work with MongoDB’s field and value pairs. This would save me the trouble of having to *design* a database to replicate LinkedIN data.
So I’ve gone through some Mac applications I wanted to test – just as well since I’m about out of power on my Mac Laptop. I’ll let this one charge and switch over to Windows 7 to try out the PC based application I mentioned in my previous open notebook entry on this subject..